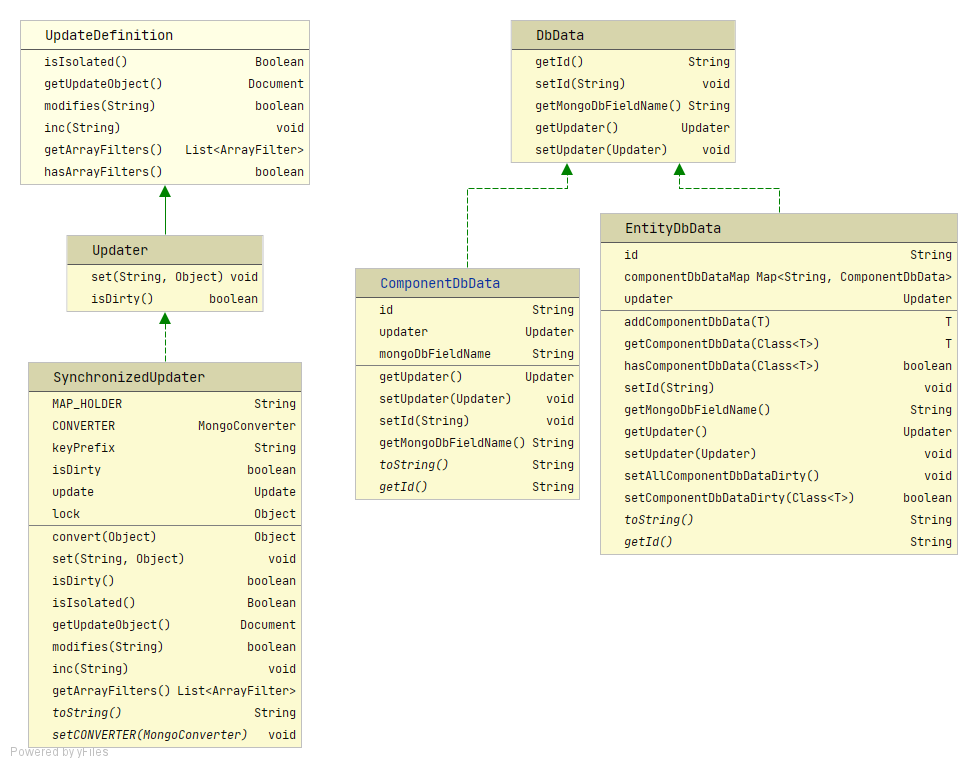
java -Xss128K com.example.demo.test.Test2 The stack size specified is too small, Specify at least 228k Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit.
消除白色误判的两种策略:1、破除上述条件一,也即增量更新(Incremental Update):如果黑色在扫描期间指向了白色,那就让它变灰;2、破除上述条件二,也即原始快照(Snapshot At The Beginning, SATB):先拍个照,当进行扫描时,不管灰色是否删除了白色的指向,都按照这个快照扫描。CMS是基于增量更新,G1、Shenandoah则是用原始快照。
筛选回收(Live Data Counting and Evacuation):1、更新Region的统计数据,并根据统计价值和成本进行排序;2、筛选Region回收集合;3、把回收Region集合中的存活对象移动到空的Region中,然后清空所有回收集合Region全部空间,由于需要移动存活对象,因此会引发STW,但是会多线程并行完成。
☺ java -XX:+PrintFlagsFinal -XX:+HandlePromotionFailure -version Unrecognized VM option 'HandlePromotionFailure' Did you mean '(+/-)PromotionFailureALot'? Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit.
上述规则调整为:只要老年代的连续空间大于等于新生代对象总大小或者历次晋升的平均大小,就会进行 Minor GC,否则将进行Full GC,换言之只有这两个条件同时满足,蔡楚发Full GC。
#在日常工作中,会遇到将制定的两行合并为一行的情况,情景为:如果发现某行包含某个字符,则将下面一行和本行合并,如下面的例子,如果行的第一个字符为a,则将后面的一行合并过来 ☺ echo'a\nb\nc\na\nb' |sed -e '/^a/N' -e 's/\n//' ab c ab
#下面两个语句是等效的:(细品) man cp | sed 's/copy/{&}/w cp.txt'#将man page中的〝copy〞字串加上大括号〝{}〞,并将current pattern space写入“cp.txt” man cp | sed -n 's/copy/{&}/p' > cp.txt
#多个FLAG可以叠加使用,但是和其他Linux指令一样,与文件有关的FLAG要放在最后 man cp | sed 's/copy/{&}/Igpw cp.txt'#不区分大小写(FLAG I)将每行 (FLAG g)的“copy”加上大括号(Command s),将pattern space输出到屏幕(FLAG p),并将current pattern space写入文件“cp.txt”(FLAG w) echo'line 1\n\nline 2\nline 3' | sed '/^$/d'#删除空白行 echo'line 1\nline 2\nline 3\nline 4' | sed -e 'N' -e 'N' -e 's/\n/+/g'#用两次N连续读取两个下一行(此时pattern space里有三行),然后把换行符都换成+,执行完毕后,输出为: line 1+line 2+line 3 line 4
var type = typeof(Dictionary<,>); Type[] typeArgs = {typeof(string), typeof(int)}; var genericType = type.MakeGenericType(typeArgs)
default关键字:在泛型类和泛型方法中产生的一个问题,给定参数化类型 T 的一个变量 t,只有当 T 为引用类型时,语句 t = null 才有效;只有当 T 为数值类型而不是结构时,语句 t = 0 才能正常使用。 解决方案是使用default 关键字,此关键字对于引用类型会返回null,对于数值类型会返回零。