[译]第一篇:G1垃圾回收器简介
对大多数人来说,Java垃圾回收器是一个可以让用户愉快处理业务的黑匣子。程序开发程序,测试(QE)验证功能,运维负责部署。在这个过程中,你可能会对堆大小、PermGen/Metaspace或线程进行一些调整,除此之外,似乎一切都运行正常。那么问题来了,当你准备打开这个匣子时会发生什么?当这些默认值不再满足需求时又将怎样呢?作为一名开发人员、测试人员、性能工程师或架构师,了解垃圾收集工作原理的基础知识,以及如何收集和分析相应的数据并将其转化为有效的调优实践,都是非常宝贵的技能。在本系列文章中,我将带你体验G1垃圾收集器,并把你从G1初学者转变为G1爱好者,并且将GC的性能优化到极致。
我们从最基本的话题开始:G1收集器的关键是什么?它是如何工作的?如果对于它的设计目标、如何决策以及如何设计没有一个综合性的理解。这就好比你设定好了目的地,但是却没有准备好交通工具或者导航地图。
G1收集器的核心目标是实现一个可预测的,软性的暂停时间,这个目标就是通过参数 -XX:MaxGCPauseMillis 定义的,与此同时也保持一贯的(consistent )应用吞吐量。最终目标是满足当今高性能的、多线程的以及堆内存不断增大的应用程序的业务需求。G1的一般性原则是:暂停时间设置得越大,可实现的吞吐量和总延迟就越高。而暂停时间目标设置得越小,可实现的吞吐量和总延迟就越低。而你使用G1的目标就是结合应用程序的运行需求、自身特性以及对于G1的理解,调整出一组参数(options),并实现业务需求下的最佳运行状态。有一点需要牢记的是:调优是一个不断循序渐进的过程,在这个过程中,你需要通过反复地测试和评估来建立测试基线和调优设置。而对于调优这件事,并不存在一个明确的指南或者说万金油参数,你需要对性能进行评估,然后调整参数,再次评估,直到达到目标要求。
对于G1来说,它通过几种不同的方式来实现这些目标。首先,就像它的名字一样,G1收集存活对象数量最少的region(也即垃圾优先!),并将存活对象压缩/转移(compacts/evacuates)到新region。其次,G1使用了一系列逐步的、并行的、多阶段的循环来满足软暂停的目标。这允许G1在规定的时间内做最必要的事情,而不必考虑整个堆的大小。
在上文中,我们引入了一个新的概念: 区域 (regions)(译注:后文统一使用region)。简单来说,一个region代表一个已分配的堆内存区间,它可以存储任何分代的对象,并且不需要和同一代的其他region保持地址连续性。在G1中,传统的年轻代(Young )和老年代(Tenured )的概念仍然存在。年轻代包含Eden区和Survivor区,对象在Eden区创建,当发生GC时,对象被转移到Survivor区。存活对象一直待在Survivor区直到它们被回收或者由于年龄超过 XX:MaxTenuringThreshold (默认值为15)晋升到老年代。老年代包括Old region,当存活对象的年龄达到 XX:MaxTenuringThreshold 时就从Survivor区晋升到该区。当然万事都有例外,我们会在后文详细讨论。当虚拟机启动时,region的数量就被计算出来了。并且遵循这么一个原则:region的数量尽量的接近2048,每个region的大小都是1MB到64MB之间,并且该值是2的指数幂(2^n)。简单举例,假设存在一个12GB大小的堆,那么:
1 | 12288 MB / 2048 = 6 MB - 6不是2的指数幂,不符合要求 |
根据上面的计算,默认情况下JVM虚拟机会分成3072个region,每个region的大小为4MB,正如如下图所示。当然,你也可以通过设置参数: -XX:G1HeapRegionSize 显式的设置region的个数。当手动设置region数量时,理解堆大小与region数量的比值就显得非常重要,因为region数量越少,G1的灵活性就会越低,扫描、标记和收集每个region所需的时间也就越长。不管什么情况下,空的region都会添加到被称为“空闲列表”(free list)的无序链表中。
![]()
虽然G1是一个分代的垃圾收集器,但是在堆空间上分配和使用并非连续的,因为它需要动态调整年轻代和老年代的配比,以达到最佳性能。当对象开始被分配时,会从空闲列表中分配一个region作为本地线程分配缓冲区(TLAB),该分配操作通过CAS确保同步性。之后对象就从该缓存区中创建而不需要额外同步。当某region的空间被对象填满后,会选择一个新的region继续填充。当所有Eden区的region都被填满时,会触发一次 转移暂停(evacuation pause , 也称作 young collection / young gc / young pause或者mixed collection / mixed gc / mixed pause),Eden区内region的数量就大致就代表了软暂停时间内需要垃圾回收的region数量。整个堆分配的Eden region的数量介于5%和60%之间,并且在每次young gc后基于本次yong gc的性能情况进行动态调整。
以下是将对象分配到非连续Eden区的示意图
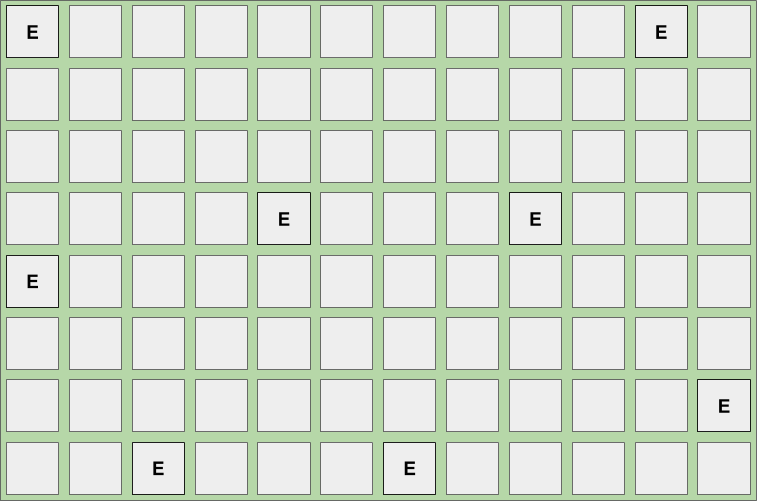
1 | GC pause (young); #1 |
根据上面的 GC pause (young) 日志,我们可以发现在 #1所示的暂停中,由于Eden区达到了 612.0M (总空间为也612.0M,一共153个region)而触发转移(evacuation)操作。整个Eden区域都被转移(0.0B)。鉴于本次GC所消耗的时间,Eden区还被缩减到532.0M(133个region)。在**#2所示的暂停中,我们看到由于达到了532.0M的上限,转移操作再次触发。并且由于暂停时间符合预期,Eden区仍然保持在532.0M**。
译注:
有些文章会把evacuation翻译为拷贝或疏散,本文使用《深入Java虚拟机:JVM G1GC的算法与实现》一书中的译法,翻译为转移
当上述young gc发生时,死亡对象被回收,存活对象被转移并压缩到Survivor区。G1收集器包含一个由G1ReservePercent(默认值为10%)明确定义的硬性边界,这个边界保证了在转移时整堆中总有一部分空间作为Survivor区。而如果没有这个硬性边界,整个堆都会被耗光直到没有内存空间用来做转移。我们并不能拍胸脯说这种情况绝对不会发生,所以说这也是一个调优参数。这一原则可以确保在每次成功转移后,之前所有分配的Eden region都返回到空闲列表中,所有被转移的生存对象最终进入Survivor区。
下图是一个标准的young gc的示意图:
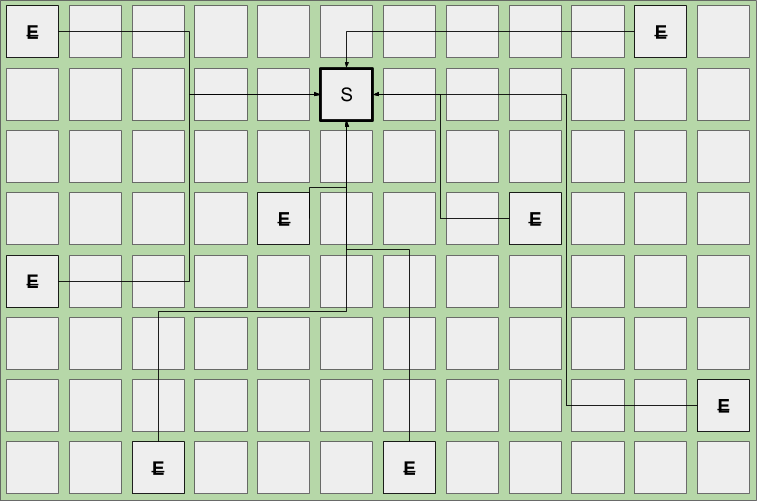
我们继续上面的流程,新对象会再次被分配到Eden区。当Eden空间被填满时,又会触发一次young gc。根据现有存活对象的年龄(所谓年龄,就是对象撑过了多少次的young gc),对象将会晋升到Old region。由于Survivor空间是年轻代的一部分,在年轻代gc(young pauses)期间,对象会被回收或者晋升。
下面是一个young gc的示例,Survivor区的存活对象被转移到一个新的Old region,而来自Eden区的存活对象被转移到新的Survivor区。而那些执行转移的region(删除线所示)会变成空的,并且重新回到空闲列表中。

G1会按照这种方式持续执行,直到遇到如下三种事件中的任意一种:
- 当G1触及到一个可配置的被称为InitiatingHeapOccupencyPercent(IHOP)的软边界。
- 当G1触及到一个可配置的硬边界:G1ReservePercent
- 当G1触发了一次大对象分配(humongous allocation,这正是上文说的那个例外,下面会详细介绍)
先讨论最常见的情形,IHOP事件代表young gc期间的某个时间点,此时Old region内的对象超过了整堆的45%(默认值)。该百分比作为young gc的一个组成部分,被不断地计算和评估。当三种情形中的任意一种被触发,就会发出请求启动并发标记周期(concurrent marking cycle)。
译注:
- 关于InitiatingHeapOccupencyPercent参数,在JDK-6976060之前,计算方式为:整堆的使用量 / 整堆大小,而之后是:Old region(包括humongous region)的使用量 / 整堆大小,具体详情可以参考 [R大的解答]([HotSpot VM] 请教G1算法的原理讨论第3页: - 资料 - 高级语言虚拟机 - ITeye群组)
- 这里所说的并发标记周期也叫做全局并发标记(global concurrent marking),指的是包括:初始标记、并发标记、最终标记、清理这几个阶段的统称,不要和其中的并发标记阶段混淆
1 | 8801.974: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: occupancy higher than threshold, occupancy: 12582912000 bytes, allocation request: 0 bytes, threshold: 12562779330 bytes (45.00 %), source: end of GC] |
G1的并发标记基于初始快照(snapshot-at-the-beginning, SATB)的原理。这意味着只有被快照“拍下”的存活对象才会参与是否为垃圾的识别,这当然是出于效率考虑。而并发标记期间任何新分配的对象都被认为是绝对存活的对象,不管它的实际存活状态如何。意识到这么一点非常重要:并发标记的时间越长,可收集对象和绝对存活对象的比值就会越大(译注:原文为:This is important because the longer it takes for concurrent marking to complete, the higher the ratio will be of what is collectible versus what is considered to be implicitly live.)。如果在并发标记期间分配的对象多于最终回收的对象,堆内存最终会被耗尽。在并发标记周期中,你会发现young gc会持续进行,因为在并发标记周期中,不是每个子阶段都会导致STW(stop-the-world)。
下图展示了当一次young gc结束后且达到IHOP 阈值时堆空间。
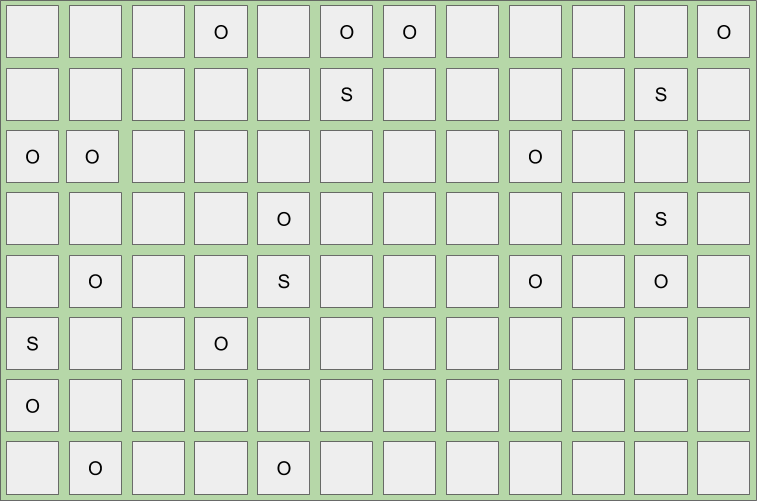
一旦并发标记周期完成,紧接着就是一次young gc,随后是第2种类型的转移,这被称为mixed gc。mixed gc和young gc的工作方式几乎相同,但是有两个主要区别。首先,mixed gc还会回收、转移并压缩被选定的Old region。其次,mixed gc的转移不同于young gc的转移。它的工作目标是尽可能快速、频繁的回收。这样做的目的是为了在软性暂停时间内最小化Eden / Survivor区的数量,使得Old region的数量最大化。
译注:
关于上面说的:最小化Eden / Survivor区的数量,可以参考:[G1Policy::calculate_young_list_desired_min_length](jdk17u/g1Policy.cpp at master · openjdk/jdk17u (github.com))
1 | 8821.975: [G1Ergonomics (Mixed GCs) start mixed GCs, reason: candidate old regions available, candidate old regions: 553 regions, reclaimable: 6072062616 bytes (21.75 %), threshold: 5.00 %] |
上面的log日志展示了一次mixed gc,候选Old region的数量(553)含有21.75%的可回收空间,这个值高于G1HeapWastePercent所规定的5%的最小阈值(JDK8u40+默认为5%,JDK7默认为10%),正因如此mixed gc被触发。鉴于不能执行费时的操作,G1会恪守垃圾优先的策略:根据候选Old region存活对象占比,决定是否将其加入到有序的回收候选列表中。如果一个Old region内的存活对象小于G1MixedGCLiveThresholdPercent 所规定的百分比(JDK8u4+默认为85%,JDK7默认值为65%),该Old region就被加入到回收候选列表中。反而言之,如果一个Old region内存活对象的比率大于65%(JDK7)或85%(JDK8u40+),G1就不再浪费时间在这次mixed gc中对其进行回收和转移。
1 | 8822.178: [GC pause (mixed) 8822.178: [G1Ergonomics (CSet Construction) start choosing CSet, _pending_cards: 74448, predicted base time: 170.03 ms, remaining time: 829.97 ms, target pause time: 1000.00 ms] |
与young gc相比,mixed gc使用相同的暂停时间,而回收的region却横跨3个region(译注:Eden、Survivor、Old)。它是通过G1MixedGCCountTarget (默认值为8)实现对Old region的逐步(incremental )回收的。具体来讲,它是将候选回收列表中Old region的数量除以G1MixedGCCountTarget (译注:假设商为X),然后在接下来的mixed gc循环中每次最少都要收集X个Old region。回收完毕后,如果可回收region仍然大于G1HeapWastePercent,mixed gc循环就会持续下去。
1 | 8822.704: [G1Ergonomics (Mixed GCs) continue mixed GCs, reason: candidate old regions available, candidate old regions: 444 regions, reclaimable: 4482864320 bytes (16.06 %), threshold: 10.00 %] |
下图展示了一次mixed gc。所有的Eden区都会被回收并转移到Survivor区。所有的Survivor区也会被回收,根据年龄的不同,足够老的存活对象会晋升到老年代。与此同时,也会选择一组Old region进行回收,这些region内的存活对象会被压缩并转移到新的Old region中。这种压缩和转移的过程可以显著减少内存碎片,同时保证空闲列表中有足够的空闲region。

下图展示了当mixed gc结束后堆内存的状态。所有的Eden区域都被回收,存活对象被转移到新分配的Survivor区域。原来的Survivor也被回收,(满足条件的)存活对象晋升到Old region中。回收候选列表中的Old region会重新返回空闲列表,同时仍然存活的对象被压缩、转移到新的Old region。
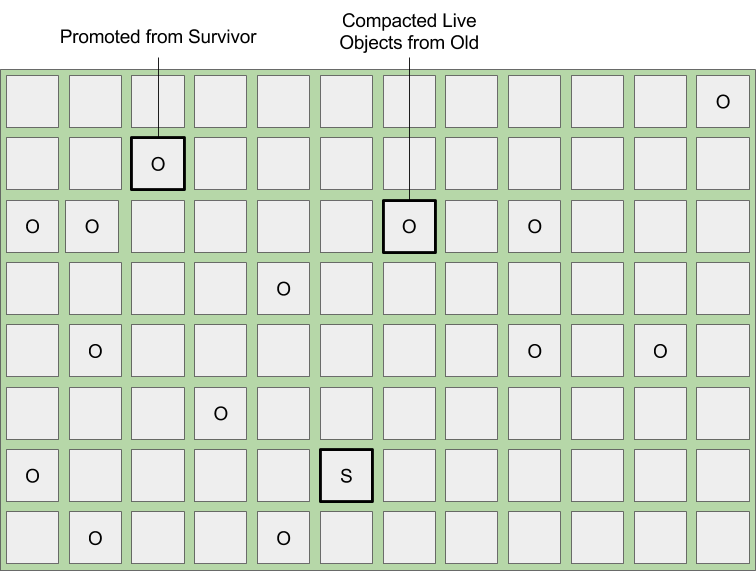
mixed gc会持续进行直到这个8次(译注:也即G1MixedGCCountTarget )循环结束,或者可回收百分比小于G1HeapWastePercent。此时,mixed gc循环结束,接下来回归到标准的young gc中。
1 | 8830.249: [G1Ergonomics (Mixed GCs) do not continue mixed GCs, reason: reclaimable percentage not over threshold, candidate old regions: 58 regions, reclaimable: 2789505896 bytes (9.98 %), threshold: 10.00 %] |
目前我们已经讨论了常见的场景。我们回过头来讨论前面提到的异常情况。这种异常就是当分配的对象大于region的50%。在这种情况下,这个对象就被认为是大对象(humongous),并且会执行专门的大对象分配(humongous allocations)。
1 | Region Size: 4096 KB |
下图展示了一个12.5MB的大对象横跨4个连续region的情况
- 大对象仅仅是一个对象,因此需要被分配到连续的region中,这可能会导致严重的碎片化。
- 大对象被直接分配到老年代中特殊的大对象region(humongous region)中。这是因为如果分配到年轻代,那么转移和复制这个大对象的成本太高。
- 尽管上图中的对象只有12.5MB,他也必须使用4个完整的region,总容量为16MB
- 大对象分配总是会触发一次并发标记循环,不管是否达到IHOP的阈值
少量的大对象分配可能不会引起什么问题,但是如果它们被持续地分配就会导致明显的碎片化,同时带来显著的性能影响。在JDK8u40之前,大对象仅在Full gc时才会被回收,对于JDK7和JDK8的早期版本来说,这个影响非常大。这就是为什么掌握应用程序中对象大小和G1的region大小是至关重要的。尽管如此,在最新的JDK8中(译注:本文写于2016年12月6日),如果你的应用程序需要分配大量的大对象,那么反复的评估和调优绝对是一件好事。
1 | 4948.653: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: requested by GC cause, GC cause: G1 Humongous Allocation] |
最后也是最不幸的是,G1也不得不执行可怕的Full GC。尽管G1会极力避免Full gc,但如果调优不当,那么Full gc就仍然是一个很残酷的现实。鉴于G1的目标是管理更大的堆内存,Full gc可能会对线上业务和SLA(译注:这是什么)造成灾难性的影响。一个最主要的原因就是G1的Full gc是单线程的。如果讨论Full gc的原因,第一个也最应该避免的原因就和元空间(Metaspace)有关。
1 | [Full GC (Metadata GC Threshold) 2065630K->2053217K(31574016K), 3.5927870 secs] |
一个最新消息是:当更新到JDK8u40+,类卸载就不再需要一次Full gc!仍然可能遇到和元空间有关的 Full gc,但这已经是UseCompressedOops及UseCompressedClassSpoInters或并发标记所需的时间有关了(我们将在以后的文章中讨论)。
接下来导致Full gc的两个原因很真实,而且往往是不可避免的。作为码农,我们的工作是尽最大努力优化和评估创建对象的代码,从而延后和避免这两种情况的发生。其中一个原因是“转移目标空间耗尽”(to-space exhausted),随之而来的是一次Full gc。这说明转移失败(evacuation failures)了,也即堆空间无法再扩展(译注:也就是达到Xmx的配置)且没有可用空间执行转移操作。如果您还记得的话,我们之前讨论过由G1ReservePercent定义的硬边界事件。这表示需要转移到to-space的空间超出了您的可用(reserve)空间,并且堆空间已经彻底满了,因此没有可用region执行转移操作。在某些情况下,如果JVM能够解决空间问题,那么后面就不会有Full gc,但这仍然是一个代价非常昂贵的STW事件。
1 | 6229.578: [GC pause (young) (to-space exhausted), 0.0406140 secs] |
如果你发现这种情形经常发生,你应该立刻意识到有很大的调优空间。另外一个原因就是并发标记期间的Full gc。在这种情况下,g1并没有转移失败,只是在并发标记完成并触发mixed gc之前用光了堆空间。这两个原因根源要么是内存泄漏,要么是对象分配和晋升的速度超过了g1的回收速度。如果 Full gc的占比很大,那么可以假设是因为对象分配和晋升有关。如果占比很小,并且最终遇到 OutOfMemoryError,那么就应该排查是否有内存泄漏。
1 | 57929.136: [GC concurrent-mark-start] |
最后,我希望这篇文章能够帮助你了解G1的设计方式,以及它是如何做出垃圾回收决策的。我希望您继续关注本系列的下一篇文章,我们将深入挖掘各种JVM参数,以收集和解释通过GC日志产生的海量数据。